허수, 「20세기 초 근대 철학서의 선택적 수용 양상 — 이돈화와 이노우에 데쓰지로」(연구계획서, 미간행)
20세기 초 근대 철학서의 선택적 수용 양상 — 이돈화와 이노우에 데쓰지로 *
연구계획서 | 허수 (서울대학교)
* 이 연구계획서는 2025년 2학기 서울대학교 국사학과 대학원 수업, “디지털 한국사 특강 — AI시대, 의미 기반 역사학의 탐색” 수업에서 수업 자료로 제시된 것이다. 아직 연구 중인 내용과 자료이므로 학술적 인용은 삼가해 주기 바란다.
1. 연구의 배경 및 필요성
연구 배경: 20세기 전반 한국의 근대 문화 형성은 일본을 통한 서양 문물의 ‘중역적(重譯的) 수용’을 특징으로 한다. 이를 규명하기 위해서는 한-일 텍스트 간의 번역 및 발췌 양상을 포착할 수 있는 방법론이 필요하다.
연구 목표:
- 《개벽》 8호(1921년 2월)에 실린 이돈화의 「科學上으로 본 生老病死」와 그 원전인 이노우에 데쓰지로(井上哲次郎)의 《철학과 종교(哲学と宗教)》(1915) 제8장을 문장(Sentence) 층위에서 정밀 비교한다.
- 텍스트 마이닝과 지식 그래프를 활용하여 두 텍스트의 관계를 직관적으로 시각화한다.
- 이를 통해 단순 번역이 아닌 ‘지식의 재구성’ 과정을 규명하는 디지털 인문학적 연구 방법론을 개발한다.
2. 데이터
Source (일본어 원문)
- 서지: 井上哲次郎, 《哲学と宗教》, 弘道館, 1915. 제8장 「메치니코프 학설에 관하여」
- 출처: 국립국회도서관 디지털컬렉션(pp.278–324)
- 처리: Google Gemini OCR → 교열 및 쪽수 기입
Target (한국어 번역문)
- 서지: 白頭山人(이돈화), 「科學上으로 본 生老病死」, 《개벽》 8호, 1921년 2월, pp.38–45.
- 출처: 국사편찬위원회 한국사데이터베이스
- 처리: EmEditor를 이용한 정제 및 단락 구분
3. 분석 방법
1단계: 데이터 구조화 (Data Structuring)
- 원문(Source, 689문장)과 번역문(Target, 175문장)에 고유 ID를 부여하였다(예: S-001, T-001).
- 1:1 번역, N:1 요약, 삭제(Untranslated)의 세 유형으로 매핑하였다.
- 산출물: Source.csv, Target.csv, Relations.csv (아래 「부록: 공개 데이터」 참조)
2단계: 핵심 주제 분석 (Text Mining)
- 도구: Python (Janome 라이브러리)
- 분석 기법: 로그우도비(LLR) 분석을 통해 ‘번역된 그룹’과 ‘삭제된 그룹’ 간의 유의미한 어휘 차이를 추출하였다.
- 3대 범주 도출:
- [과학과 생존] — 번역본에 포함(콜레라, 세포, 방법 등)
- [철학의 배제] — 번역본에서 삭제(자살, 정신, 인성, 히스테리 등)
- [권위의 삭제] — 번역본에서 삭제(괴테, 다윈, 후펠란트 등 인명)
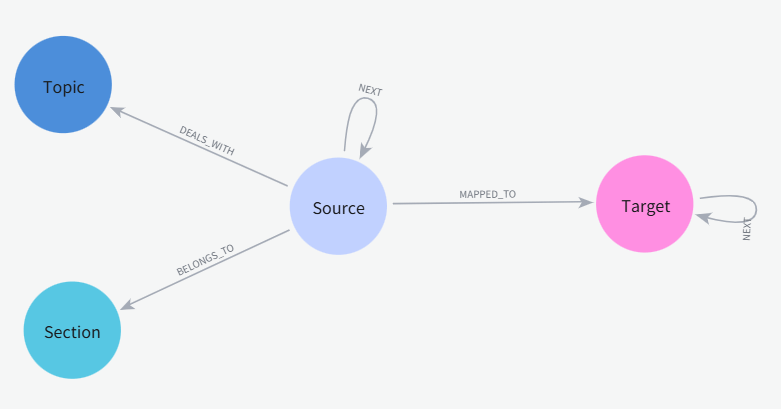
3단계: 지식 그래프 구축 (Neo4j)
- 노드(Node): 문장(Source/Target), 주제(Topic), 영역(Section)
- 엣지(Edge): 흐름(NEXT), 번역 관계(MAPPED_TO), 주제 분류(DEALS_WITH), 영역 소속(BELONGS_TO)
- Cypher 쿼리: 노드·엣지 생성 및 영역 분류 (아래 「부록: 공개 데이터」 참조)
[그림] 데이터 모델(온톨로지) 구조
4. 시각화 및 분석
시각화 결과
[그림] Neo4j 지식 그래프 분석 결과
| 전체 구조 비교 | [과학과 생존] | [철학, 권위] |
|---|---|---|
 |  |  |
| 긴 원문(파랑) 중 일부만 압축되어 번역문(분홍)으로 연결됨 | 초록색 노드(과학 어휘)는 대부분 번역문으로 살아남아 연결됨 | 철학(빨강) 및 권위(노랑) 관련 노드는 번역되지 못하고 원문 단계에서 단절됨 |
분석
1. 텍스트 형식과 문체의 변화
- 강연에서 논설로: Source는 청중 대상의 구어체와 여담이 많은 반면, Target은 독자를 위한 객관적 평서문으로 재구성되었다.
- 압축과 효율: 원문의 핵심 논리만 추려내어 분량이 약 1/3 수준으로 대폭 축소되었다.
- 개념의 현지화: 복잡한 생물학적 설명은 당시 조선 지식인이 이해하기 쉬운 국한문 혼용체로 간결화되었다.
2. 데이터 분석 결론: 선택적 수용의 증명
- 그래프가 보여주는 사실: 원문의 흐름(NEXT)이 번역 과정(MAPPED_TO)에서 끊어지는 지점들이 무작위가 아니다.
- 이돈화의 의도: 서구의 지식을 수용하되, 이노우에 데쓰지로의 ‘형이상학적 권위와 사변’은 철저히 배제하고, 조선 사람에게 필요한 ‘실용적인 생존 과학’만을 선택적으로 수용하여 전달하였다.
- 의의: 단순한 번역이 아닌, 식민지 지식인의 주체적인 지식 편집과 재맥락화 과정을 데이터를 통해 실증하였다.
5. 참고문헌
- 허수, 「1920년대 초 『개벽』 주도층의 근대사상 소개양상 — 형태적 분석을 중심으로」, 《역사와 현실》 67, 2008년 3월, pp.47–76.
6. 연구 소감
- 이미 형성한 구조 위에 필요에 따라 새롭게 추가하는 것이 용이한 ‘그래프DB’의 장점을 확인할 수 있었다.
- 단행본, 언론 텍스트의 발췌 및 번역 양상을 규명하는 유용한 분석틀이 될 수 있다.
- LLM(구글 제미나이)과 지식 그래프(Neo4j)의 결합을 통해 분석의 효율성을 경험하였다. 향후 이를 연구 자동화 방안 모색으로 발전시킬 필요가 있다.
부록: 공개 데이터
본 연구의 재현가능성과 투명성을 위해, 분석에 사용된 데이터와 코드를 아래에 공개한다.
데이터 파일 (CSV)
| 파일명 | 내용 | 규모 |
|---|---|---|
| Source.csv | 일본어 원문 — 문장별 ID, 문단 ID, 페이지, 원문 텍스트 | 689문장 |
| Target.csv | 한국어 번역문 — 문장별 ID, 문단 ID, 페이지, 번역 텍스트 | 175문장 |
| Relations.csv | 원문-번역문 매핑 — Source ID, Target ID, 관계 유형(1:1 번역/N:1 요약/제목 변형), 구조적 분석 비고 | 매핑 전수 |
Neo4j Cypher 쿼리
| 파일명 | 내용 |
|---|---|
| Cypher문.txt | 그래프 기본 구조 생성 — ① Source·Target 노드 생성, ② 문장 순서(NEXT) 연결, ③ 원문-번역문 매핑(MAPPED_TO) |
| Cypher문-1.txt | 영역(Section) 분류 — 원문 689문장을 내용에 따라 6개 영역(도입/생물학적 부조화/생존욕과 염세주의/기존 해법/과학적 해법/결론)으로 분류하고 BELONGS_TO 관계로 연결 |
